CUDA
En los últimos años, la computación en paralelo ha experimentado un auge notable. Existe un gran interés en mejorar la eficiencia de aplicaciones que, tradicionalmente, han mostrado un rendimiento pobre en su forma secuencial. El aumento de la frecuencia en las CPUs, uno de los principales motores de su avance, ya no es suficiente. Problemas en la disipación de calor y en la escala de integración lo impiden. Por ello, los principales fabricantes han venido introduciendo modelos de varios núcleos desde 2005.
En este contexto, NVIDIA desarrolla CUDA. Es una arquitectura que, junto con un API, permite la programación de aplicaciones paralelas para procesadores gráficos (GPUs). Ciertos programas experimentan una notable mejoría en esta plataforma. Es por ello que decidí usarla en mi Proyecto Fin de Carrera, titulado «Segmentación de Imágenes en CUDA».
Segmentación de imágenes
La segmentación consiste, básicamente, en separar una imagen en sus partes constituyentes u objetos. En el ejemplo a continuación (figuras 1 y 2), los pimientos se dividen por zonas coloreadas:


Existen muchos métodos de segmentación, que pueden clasificarse en: umbralización, por bordes, por regiones, y técnicas híbridas. Dentro de este último grupo, se encuentra el crecimiento de regiones con semilla («seeded region growing»), que fue el escogido en mi trabajo.
Crecimiento de regiones
Crecimiento de regiones aprovecha que píxeles espacialmente cercanos tienen valores de intensidad similares. Comienza por uno solo, denominado semilla, al que se van añadiendo otros cercanos progresivamente. El proceso consta de tres pasos:
- Elegir un punto semilla.
- Comprobar los puntos vecinos y añadirlos a la región si son similares a la semilla.
- Repetir el segundo paso para cada uno de los nuevos puntos añadidos, hasta que no quede ninguno por incluir.
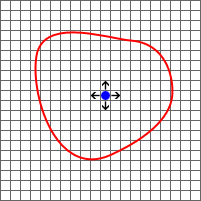
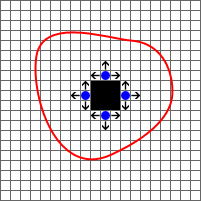
En la figura 3 se puede observar la semilla, de color azul, y las flechas que indican los puntos vecinos. La línea en rojo representa el contorno del segmento que deberíamos obtener al final del proceso. A la derecha (figura 4) se muestra el estado una vez acabada la primera iteración. Puesto que los puntos vecinos son similares a la semilla (todos están dentro del segmento) se incluyen en la región, coloreada en negro. Al igual que antes, se vuelven a comprobar los vecinos de esos nuevos puntos. Este proceso es bastante similar al de una inundación. El agua sale de un manantial (semilla) y va anegando los alrededores paulatinamente.
Implementación
División del trabajo
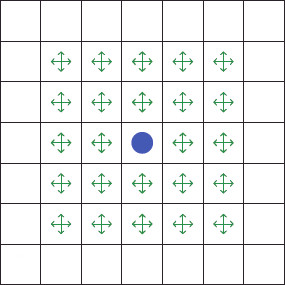
La filosofía de un programa paralelo es ejecutar varias tareas a la vez, con la intención de acabar antes. Una imagen de tamaño medio suele tener varios miles de pixels. En mi caso, asignaba un hilo a cada uno de ellos. Los hilos comprueban pixels vecinos (figura 5) para ir así expandiendo la región.
En CUDA, los hilos se organizan en bloques, que en en el programa tienen dos dimensiones y siguen la estructura de la figura anterior.
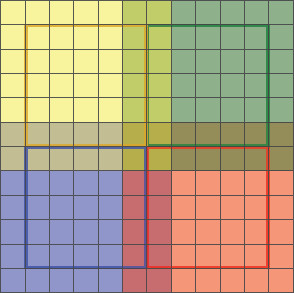
Los pixels perimetrales no muestran hilos porque, al contrario que los interiores, tienen menos de 4 vecinos. Por ejemplo, el límite izquierdo no tiene vecinos izquierdos, el inferior no tiene inferiores, y homólogamente con el derecho y superior. Vigilar esto en el código implicaría añadir demasiada lógica de control. Eliminando hilos de la periferia solucionamos este inconveniente, aunque creamos otro: espacios entre bloques. Esto se arregla solapándolos (figura 6):

Juntando Regiones
Una vez que los bloques finalizan la segmentación en su zona (figura 7), hay que juntar las regiones, si es que procede. Para ello se realizan dos «pasadas» a la imagen en sentidos opuestos (más detalles en la memoria).
Rendimiento
En un programa paralelo el rendimiento cobra especial relevancia. Por ello, se analizaron dos aspectos. Por una parte, la sustitución de «operaciones atómicas» por «reducción paralela» en el cálculo de una media del color, logrando una aceleración de 3.57. Por otra, la influencia de las dimensiones de bloque en la coalescencia.
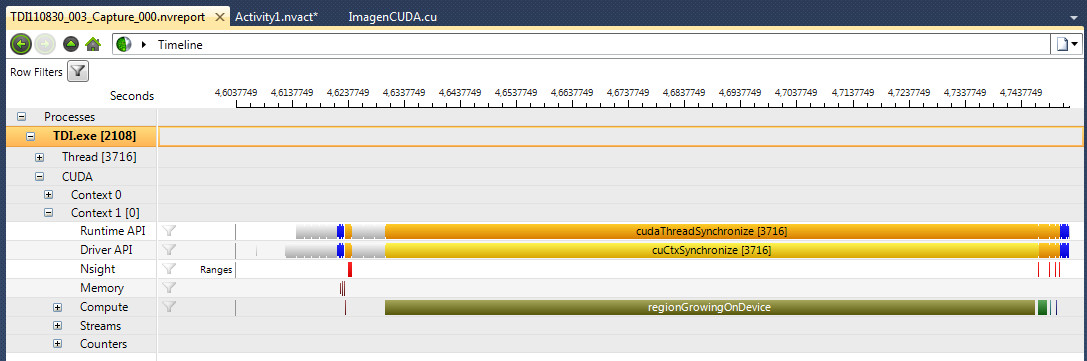
En mi trabajo, se empleó la función «Application Trace» del fantástico depurador Parallel Nsight, que proporciona tiempos y cronogramas detallados de cada uno de los kernels (figura 8):
Programa final
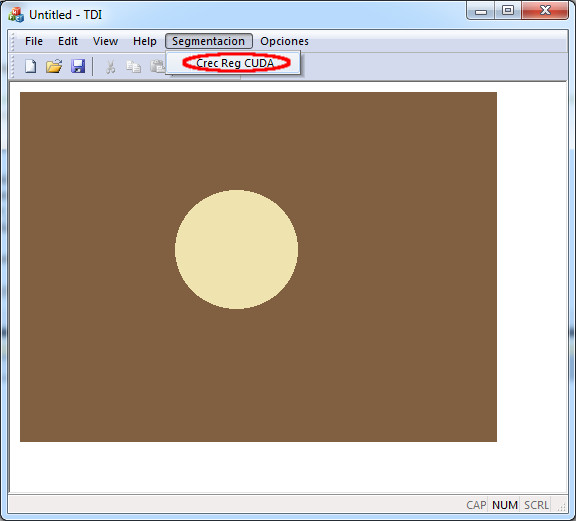
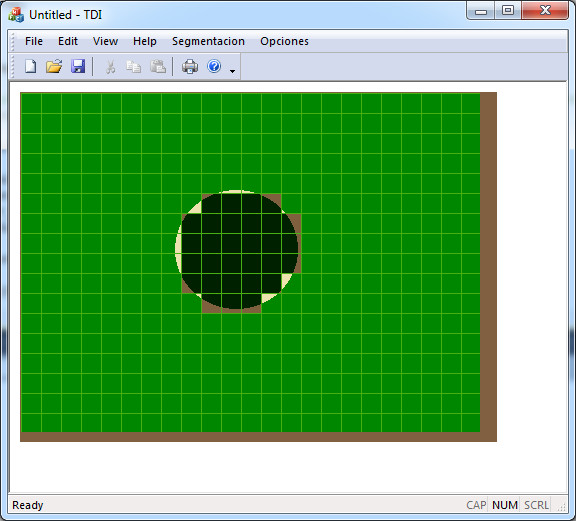
La apariencia final del programa se puede comprobar en la figura 9. Presenta una interfaz visual, desarrollada en MFC. Se incluye una caja de diálogo para la selección de GPU, en caso de que hubiese varias, y diagnósticos de detección. La imagen de ejemplo en la figura 9 se muestra una vez segmentada en la figura 10.
Descargas:
- Memoria (3.23 MiB), PDF (De especial relevancia los capítulos 5 y 6).
- Código y ejecutables (5.1 MiB), ZIP